
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Matrix Factorization
- BFS
- 안드로이드스튜디오
- 어렵다
- MSBuild
- 컨트리뷰톤
- Github
- WebOS
- 대학원
- SQL
- level1
- git
- D3
- Python
- SWEA
- level4
- 내휴학생활중의아주큰일
- 파이썬
- py
- build
- 다시풀기
- 프로그래머스
- 휴학
- 컴퓨터비전
- androidstudio
- 자바
- 대학원일기
- level3
- LEVEL2
- java
- Today
- Total
bit가 눈 앞에서 왔다갔다
Py) 프로그래머스 17676 [1차] 추석 트래픽 본문
https://programmers.co.kr/learn/courses/30/lessons/17676
코딩테스트 연습 - [1차] 추석 트래픽
입력: [ "2016-09-15 20:59:57.421 0.351s", "2016-09-15 20:59:58.233 1.181s", "2016-09-15 20:59:58.299 0.8s", "2016-09-15 20:59:58.688 1.041s", "2016-09-15 20:59:59.591 1.412s", "2016-09-15 21:00:00.464 1.466s", "2016-09-15 21:00:00.741 1.581s", "2016-09-1
programmers.co.kr
1차 시도: 2시간 반
2차 시도: 30분
0. 입출력
- 입력: [
"2016-09-15 01:00:04.001 2.0s",
"2016-09-15 01:00:07.000 2s"
] - 출력: 1
1. 내 접근
① 각 정렬된 것들의 시작점 +1초가 얼마나 많이 포함하는지 확인해야겠다. -> 시작점 구해야함
② split()해서 각각의 시간, 분, 초를 모두 time이라는 리스트에 저장하고, 3씩 뛰어서 ss.sss를 확인하자
ss.sss - 걸린시간 을 계산해서 시작점을 확인한다.
②-1 만약 걸린시간 > ss.sss라면, 시간 -1, 분 +59, 초+60 을 해서 계산하자
③ 계산이 완료된 후 start 리스트에 넣는데, 이때 : 를 쓰지 말고 그냥 float 형태의 수로 다 이어 붙여서 append하자
④ 이후 범위ㅣ 확인
1-1. 고민
2016-09-15 hh:mm:ss.sss 인데, 위의 ②-1번과 같은 상황에 어떻게 처리해줘야할까가 까다로웠다.
이거 고민하면서 시간을 너무 많이 써버림..
1-2. 내 코드 -> 틀림
def solution(lines):
answer = 0
start = []
time = []
for line in lines:
for i in range(3):
time.append(line.split()[1].split(':')[i])
time.append(line.split()[2].split('s')[0])
print(time)
for sec in range(0, len(time), 4):
second = float(time[2+sec])
tsecond = float(time[3+sec])
if tsecond > second:
second += 60
time[1+sec] -= 1
tmp = second - tsecond
start.append(float(''.join([time[sec], time[1+sec], str(tmp)])))
for point in range(len(start)):
a = 0
for check in start[point:]:
if start[point] <= check <= start[point]+1:
a+=1
if answer < a:
answer = a
return answer고칠 것들 투성인데 머리가 너무 멍해서 뭘 더 할수가 없었다..
2. Solution
from datetime import datetime, timedelta
def solution(lines):
answer = 0
lines_list = [list(line.split()) for line in lines]
start_end_times = []
check_times = []
for D, S, T in lines_list:
mili_sec = int(round(float(T[:-1]), 3) * 1000 - 1)
end = datetime.strptime(D + ' ' + S, "%Y-%m-%d %H:%M:%S.%f")
start = end - timedelta(milliseconds=mili_sec) # ....?
start_end_times.append((start, end))
check_times.append(start)
check_times.append(end)
cnt_list = []
for i in range(len(check_times)):
traffic_start = check_times[i]
traffic_end = traffic_start + timedelta(milliseconds=999)
cnt = 0
for start, end in start_end_times:
# 끝점이 트래픽 시간에 포함
if start <= traffic_start and end >= traffic_start:
cnt += 1
# 시작점이 트래픽 시간에 포함
elif start <= traffic_end and end >= traffic_end:
cnt += 1
# 모든부분이 트래픽 시간에 포함
elif start >= traffic_start and end <= traffic_end:
cnt += 1
cnt_list.append(cnt)
answer = max(cnt_list)
return answer
3. 새롭게 알게 된 것
from datetime import datetime, timedelta
datetime: 날짜와 시간 저장
date: 날짜만 저장
time: 시간만 저장
timedelta: 시간 구간 정보 저장
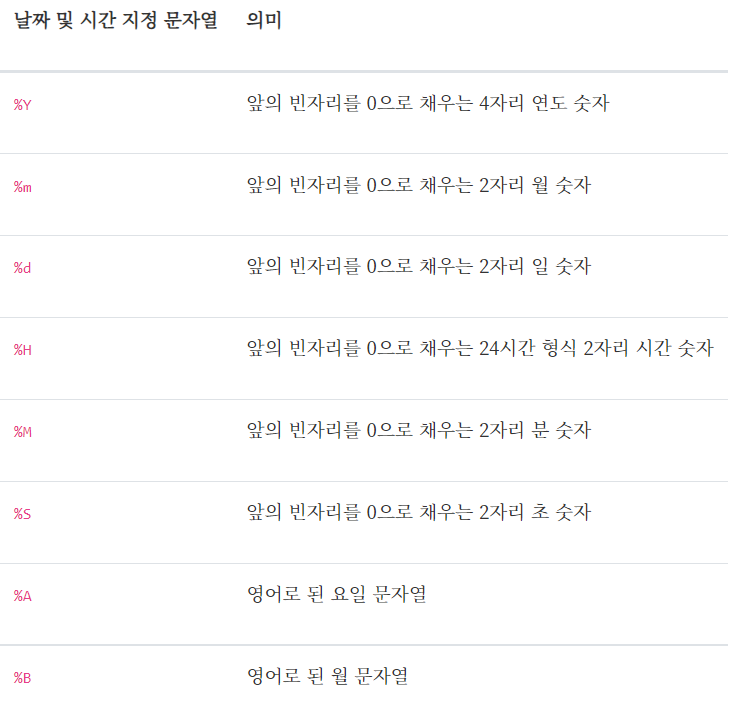
strptime(datetime 오브젝트로 변환될 문자열, format code)
round(대상 수, 자릿수) : 반올림
'Algorithm > Prob' 카테고리의 다른 글
| Py) 프로그래머스 64061 크레인 인형뽑기 게임 (0) | 2022.03.23 |
|---|---|
| Py) 프로그래머스 62048 멀쩡한 사각형 (0) | 2022.03.18 |
| Py) 프로그래머스 64063 호텔 방 배정 (0) | 2022.03.11 |
| Py) 프로그래머스 67259 경주로 건설 (0) | 2022.03.10 |
| SQL) 95410, 95043 (0) | 2022.03.05 |



