
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- Python
- 다시풀기
- Matrix Factorization
- 내휴학생활중의아주큰일
- git
- level3
- level4
- 대학원일기
- 파이썬
- SQL
- 컨트리뷰톤
- 프로그래머스
- level1
- Github
- 컴퓨터비전
- 어렵다
- 자바
- androidstudio
- 대학원
- 휴학
- LEVEL2
- BFS
- D3
- MSBuild
- WebOS
- java
- py
- 안드로이드스튜디오
- build
- SWEA
- Today
- Total
bit가 눈 앞에서 왔다갔다
컴퓨터 비전 - YOLOv3 본문
git clone https://github.com/pjreddie/darknet cd darknet makewget https://pjreddie.com/media/files/yolov3.weights이후 detector 실행
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg #또는 ./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg예시 이미지나 직접 추가한 이미지로 모델을 돌려볼 수 있다.
신뢰도가 출력 되고 predictions.jpg라는 파일명으로 결과가 저장된다.
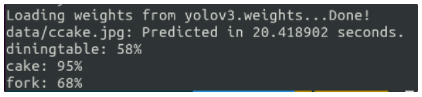

명령어를 계속 입력하지 않고 반복적으로 이미지 경로만 입력하게 할 수 있다.
./darknet detect cfg/yolov3.cfg yolov3.weights이후 나오는 Enter Image Path에는 이미지 경로만 입력하면 된다.
*
YOLO는 따로 설정하지 않으면 .25 이상의 신뢰도를 보이는 것을 답으로 출력한다.
아래 명령어로 해당 수치를 변경할 수 있다.
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0.0으로 입력할 경우 0%도 전부 출력하게 된다.
Pascal VOC 데이터셋을 이용해 모델을 직접 학습 시킬 수 있다.
- Pascal VOC 데이터를 불러오기
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar tar xf VOCtrainval_11-May-2012.tar tar xf VOCtrainval_06-Nov-2007.tar tar xf VOCtest_06-Nov-2007.tarVOCdevkit/ 를 확인하면 VOC training data가 있는 서브 디렉토리를 확인할 수 있다
- 라벨 생성하기
Darknet은 각 이미지의 정보가 저장된 txt 파일의 형태를 이용해야한다.
<object-class> <x> <y> <width> <height>
Darknet scirpts/ 디렉토리의 voc_label.py를 이용해 라벨 txt 파일을 생성한다.
wget https://pjreddie.com/media/files/voc_label.py python voc_label.py(참고)
voc_label.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()VOCdevkit/VOC2007/labels/ 와 VOCdevkit/VOC2012/labels/에 라벨 파일이 생성된 것을 확인할 수 있다.
- 2007 test 파일(test 용이므로)을 제외하고 나머지를 학습시킨다
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt- cfg를 수정한다.
vi cfg/voc.data 1 classes= 20
2 train = <path-to-voc>/train.txt
3 valid = <path-to-voc>2007_test.txt
4 names = data/voc.names
5 backup = backup의 자리에 train.txt와 2007_test.txt의 파일 위치를 입력한다.
두 txt 파일 모두 같은 위치에 있다.
- 훈련
wget https://pjreddie.com/media/files/darknet53.conv.74 ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74- Input : 416x416 sized imaeg
- Process : extract feature maps
- Output : 52x52, 26x26, 13x13 sized feature maps
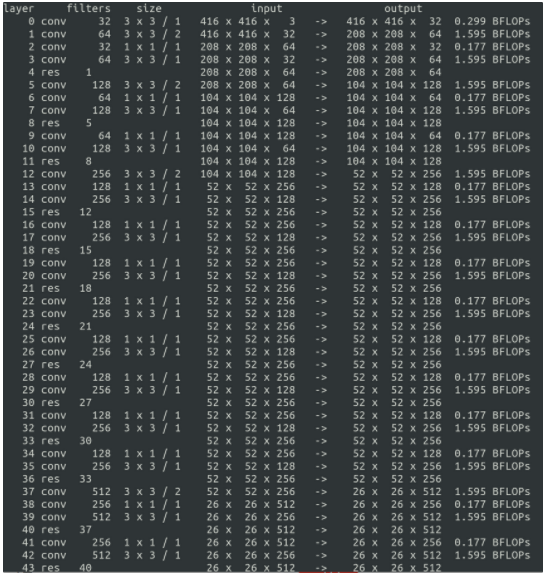


학습 시킬 때 뜨는 것들이 정확히 뭘 의미하는지 너무 궁금해서 알아봤다.
YOLOv3 내부 구조에 대해 논문 써놓은 걸 누가 리뷰 해놓은게 있길래 참고 했다.
YOLOv3 동작 방식, 내부 구조 참고 - https://herbwood.tistory.com/21
*
참고 -1

299 - 연산횟수
14.474660 - 평균 손실율 : 평균 손실율이 줄어들지 않는다면 학습을 중단할 것.
참고-2
darknet/backup 디렉토리에 들어가면 각 가중치 별로 파일이 생성되어있다.
darknet/data에 있는 testdata를 옮겨주고 진행
'인턴십 > KISTI' 카테고리의 다른 글
| KISTI 한달 인턴십 후기, 느낀점 - 기, 승 (0) | 2022.02.23 |
|---|---|
| 컴퓨터 비전 - MaskRCNN (0) | 2022.02.22 |
| 컴퓨터 비전 - Docker, Anaconda3 (0) | 2022.02.18 |
| 컴퓨터 비전 - 초기 환경 설정 (0) | 2022.02.18 |
| YOLOv3은 우리집 개를 고양이로 인식할까? (2) | 2022.02.10 |



